






1. N-TILE
It creates N-Number of groups by deviding the resultset into N-number of groups. Each group is identified by a serial number.Syntax:
NTILE(integer_exp) OVER( [ <partition_by_clause> ] < order_by_clause >)
Examples
| SELECT region, NTILE(4) over(order by region) FROM Employee |
SELECT region,
NTILE(3) over(order by region) FROM Employee |
SELECT region,
NTILE(1) over(order by region) FROM Employee |
|||
|---|---|---|---|---|---|
| OUTPUT | OUTPUT | OUTPUT | |||
| Region | Region | Region | |||
| East | 1 | East | 1 | East | 1 |
| East | 1 | East | 1 | East | 2 |
| North | 1 | North | 1 | North | 3 |
| North | 2 | North | 2 | North | 4 |
| North | 2 | North | 2 | North | 5 |
| South | 3 | South | 2 | South | 6 |
| South | 3 | South | 3 | South | 7 |
| West | 4 | West | 3 | West | 8 |
| West | 4 | West | 3 | West | 9 |
NTILE(No.of rows)= Row_NUMBER(), see NTILE(1) example of above.
2. Over (PARTITION-clause)
Using Over(Partition) clause you can do two thing:- You can apply Aggregate functions on different columns simultaneously in single SELECT.
- You can SELECT columns with Aggregate functions without GROUP-BY clause.
Example:
USE AdventureWorks;
GO
SELECT SalesOrderID, ProductID, OrderQty ,
SUM(OrderQty) OVER(PARTITION BY SalesOrderID) AS Total,
AVG(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Avg" ,
COUNT(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Count" ,
MIN(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Min" ,
MAX(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Max"
FROM Sales.SalesOrderDetail
WHERE SalesOrderID IN(43659,43664);
GO
SELECT SalesOrderID, ProductID, OrderQty ,
SUM(OrderQty) OVER(PARTITION BY SalesOrderID) AS Total,
AVG(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Avg" ,
COUNT(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Count" ,
MIN(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Min" ,
MAX(OrderQty) OVER(PARTITION BY SalesOrderID) AS "Max"
FROM Sales.SalesOrderDetail
WHERE SalesOrderID IN(43659,43664);
OUTPUT :

3. COMPUTE-BY Statement
- It adds summary report computed with aggregate function to result set.
- Used to generate additional summary at the end of the result set.
- The beauty of COMPUTE is that you can nest multiple aggregate function in single statement. e.g, COMPUTE MIN(SUM(salary));
- The result of Query containing COMPUTE is invisible using Visual Studio, use Sqlcmd instead.
- BY clause is optional, if present then ORDER BY clause with same expression must exists, otherwise it is error.
- COMPUTE is applied to result of all aggregate function. i.e, to all groups. Therefore, you can use it to find Minimal/maximum group.
- COMPUTE BY is applied to each group(i.e, within group) not all groups(i.e, not among all group). Therefore, you can use it to find sub-totals of each groups.>/li>
Syntax:
COMPUTE { Aggregate Function1} ( expression ) } [ Ag.Func2 ,...n ]
[ BY expression [ ,...n ] ]
[ BY expression [ ,...n ] ]
Examples:
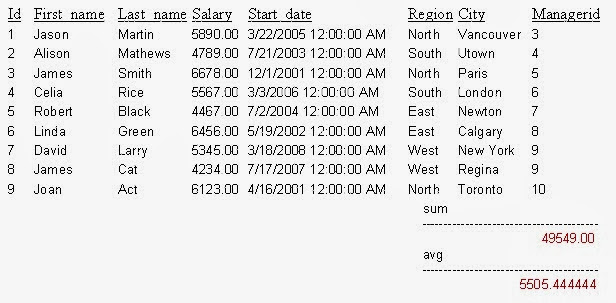
Find sum and average of salaries of employees.
SELECT id, first_name, last_name, salary,
start_Date, region, city, managerid
FROM Employee
COMPUTE SUM(salary), AVG(salary)
GO
OUTPUT:
Find the smallest salaried region
SELECT SUM(salary) AS Expr1
FROM Employee
GROUP BY region
COMPUTE MIN(SUM(salary))OR SELECT MIN(t1) As Expr1,
FROM (SELECT SUM(salary)
FROM Employee
GROUP BY region)
OUTPUT:

Invalid Solutions-
Invalid-1: The following raises an error because Aggregate function cannot take aggregate function as parameter
SELECT Min(Sum(Salary)) -- Error.
From Employee
Group By Region -
Invalid-2: The following returns Minimum value in each region. But not minimal valued region in all regions.
SELECT MIN(salary)
From Employee
Group By Region
-
-
Find the sub-totals with details for each regions. (using COMPTUE BY )
COMPUTE BY is applied to each group not all groups as whole. Note that it must be followed by ORDER BY clause with same column.
SELECT salary, region
FROM employee
ORDER BY region
COMPUTE SUM(salary) by region
OUTPUT


It is similar to SELECT SUM(salary), AVG(salary). But not followed by Query res
4. Group By with CUBE| ROLLUP
( a.k.a Grouping Sets Operators )
- CUBE and ROLLUPs are extentions to GROUP-BY that adds additional Summary to result-set.
- When SELECT query contains GROUP with CUBE | ROLLUP, it returns two result sets; one result set for query execution output and second for Summary.
- The ouput is similar to writing two queries by combing using UNION-ALL, but SETS-Operators are more efficient to write.
Syntax:
GROUP BY expression[,..n] [WITH {CUBE | ROLLUP} ]
Examples :
Let us consider a M:M:M relationship. E.g, Employees:Projects:TeamLeader where- Each project have multiple employees, and each employee works in multiple project.
- Each project is handled by multiple Team Leaders and each Team leader lead multiple projects.

A: CUBE:
CUBE: Appends summary report of all possible combinations of values in aggregate columns.-
Find TOTAL and SUB-TOTAL for each Project, Employee (All combinations PROJECT: EMPLOYEE)
Query OUTPUT SELECT Project, [Emp Name],
COUNT(*) [No of Employees]
FROM Table1
GROUP BY Project, [Emp Name] WITH CUBE
=
SELECT Project, [Emp Name], COUNT(*) FROM Table1
GROUP BY Project, [Emp Name]
UNION ALL
Select NULL, NULL, Count(*) FROM Table1
UNION ALL
Select NULL, [Emp Name], Count(*) FROM Table1;
GROUP BY [Emp Name]
-
Find TOTAL and SUB-TOTAL for each Project, Employee, TeamLeader Groups.
SELECT Project, [Emp Name], [TeamLeader], COUNT(*) AS [No of Times]
FROM Table1
GROUP BY Project, [Emp Name] , [TeamLeader] WITH CUBE
OUTPUT



B: ROLL UP
- Similar to CUBE it appends summary report to resultset, but works with only single combination of values specified in function.
- It enables a SELECT statement to calculate multiple levels (hierarchical) of aggregate value (e.g. subtotals) across a specified group of dimensions. and whole-level of aggregate value(e.g., grand total.)
-
Find TOTAL and SUB-TOTAL no. of Employees in each Project ( ie., Single group Combination)
SELECT Project, [Emp Name], COUNT(*) AS [No of Employees]
FROM Table1
GROUP BY Project, [Emp Name] WITH ROLLUP
=
Select Project, EmpName, Count(*) FROM Table1
GROUP BY Project, EmpName
UNION ALL
Select NULL, NULL, Count(*) FROM Table1
OUTPUT


ROLLUP simply summarizing data hierarchically whereas CUBE summarizing as whole.
5. GROUPING - Row indicator for CUBE | ROLLUPs
- It differentiates stored values (NULL or Not-NULL) from NULL values created by ROLLUP/CUBE NULL.
- It returns 1 if row is ROLLUP(/CUBE) have NULL-value otherwise 0.
- It identifies in which rows Total and Sub-totals.
- The main usage is to do decoration to ROLLUP/CUBE summery result.
Examples:
Example-1: Show what changes are made by GROUPING()verb
| Without GROUPING() | With GROUPING() | ||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
SELECT Project, [Emp Name] FROM Table1 GROUP BY Project, [Emp Name] WITH ROLLUP |
SELECT Project, GROUPING([Emp Name]) FROM Table1 GROUP BY Project, [Emp Name] WITH ROLLUP |
||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Example-2: Decorating with GROUPING()
SELECT
CASE WHEN GROUPING([Project])=1
THEN 'All Projects'
ELSE [Project ] END,
CASE WHEN GROUPING([Emp Name])=1
THEN 'Total Emps'
ELSE [Emp Name] END AS [Employees],
COUNT(*) AS [No of Employees]
FROM Table1
GROUP BY Project, [Emp Name] WITH ROLLUP
CASE WHEN GROUPING([Project])=1
THEN 'All Projects'
ELSE [Project ] END,
CASE WHEN GROUPING([Emp Name])=1
THEN 'Total Emps'
ELSE [Emp Name] END AS [Employees],
COUNT(*) AS [No of Employees]
FROM Table1
GROUP BY Project, [Emp Name] WITH ROLLUP
| Project | Emp Name | Employees |
|---|---|---|
| Project1 | e1 | 1 |
| Project1 | e2 | 1 |
| Project1 | e3 | 1 |
| Project1 | e4 | 1 |
| Project1 | Total | 4 |
| Project2 | e1 | 1 |
| Project2 | e2 | 1 |
| Project2 | Total Emps | 2 |
| Project3 | e1 | 1 |
| Project3 | e4 | 1 |
| Project3 | Total Emps | 2 |
| All Projects | Total Emps | 8 |
Hi
ReplyDeleteIt was really a nice article and I was really impressed by reading this article. You can also visit here…
MS SQL Corporate Training
Nice and good article.Thanks for sharing this useful information. If you want to learn dotnet course in online, please visit below site.
ReplyDeletedotnet Online Training, dotnet course, dotnet online training in kurnool, dotnet online training in hyderabad, dotnet online training in bangalore, online courses, online learning, online education, trending courses, best career courses
Great post thanks forsharing for more update at
ReplyDeleteDot Net Online Training Bangalore
Hello, I would like to thank you for such an interesting and extremely Informative Blog.
ReplyDeleteIf anyone wants to know about best Ielts Coaching Classes in Chandigarh please visit International Ielts Center.
Global Visa Destination is the best Australia Study Visa Consultants in Chandigarh. Who can provide you assistance related to study visa for Australia in India
ReplyDeleteSix Photo Snuff provides Premium Snuff prepared by using pounded tobacco leaves. We are the best snuff company in India for traditional snuff, herbal snuff, and premium snuff.
ReplyDeleteFurosap is the best medicine for men to Maintains Healthy Testosterone Levels with no side-effects. It is available at an affordable price, to buy, please visit our website.
ReplyDeleteLearn data visualization and analytics withTableau training india online designed for beginners to advanced learners.
ReplyDelete"Enroll in the best best tableau training to master data visualization and analytics skills. Gain hands-on experience and become proficient in creating insightful dashboards."
ReplyDeleteLearn UI/UX design with OnlineITGuru and master wireframing, prototyping, user research, and design tools to create intuitive digital experiences.
ReplyDeleteui ux designer training
Build strong Java programming skills with OnlineITGuru by learning core Java, OOP concepts, and real-world application development.
ReplyDeletejava programming online
Learn data modeling with OnlineITGuru and gain expertise in ER diagrams, normalization, and database design for scalable systems.
ReplyDeletebest data modelling courses
Master AWS DevOps with OnlineITGuru by learning CI/CD pipelines, Docker, Kubernetes, and cloud automation for modern deployments.
ReplyDeletebest devops course
Learn power bi classes online
ReplyDeletedesigned to help you master data visualization, reporting, and analytics from anywhere. Build job-ready Power BI skills with expert-led, flexible online training.
Learn data visualization and analytics with tableau course online
ReplyDelete, designed for beginners to advanced users.
"Enhance your career with expert salesforce dev training
ReplyDeletedesigned to build strong development skills. Gain hands-on experience and master Salesforce tools to excel in real-world projects."